
مقدمه
محاسبات موازی به طور پیوسته در حال تبدیل شدن به یک ضرورت در دنیای امروز است. با افزایش پیچیدگی مسائل محاسباتی و نیاز به پردازش حجم عظیمی از دادهها، استفاده از قدرت پردازش موازی به عنوان یک راهکار کلیدی مطرح شده است. در این میان، CUDA (Compute Unified Device Architecture) به عنوان یک معماری محاسباتی موازی و مدل برنامهنویسی قدرتمند، نقش برجستهای ایفا میکند. CUDA توسط شرکت NVIDIA توسعه داده شده و به برنامهنویسان اجازه میدهد تا از قدرت پردازشی واحدهای پردازش گرافیکی (GPU) NVIDIA برای محاسبات عمومی استفاده کنند.
تاریخچه و مفهوم CUDA
در گذشته، GPU ها عمدتاً برای رندر کردن گرافیک و تصاویر در بازیها و نرمافزارهای گرافیکی به کار میرفتند. با این حال، معماران NVIDIA دریافتند که قدرت پردازش موازی بالای GPU ها میتواند برای طیف وسیعتری از محاسبات عمومی نیز به کار گرفته شود. CUDA به عنوان پاسخی به این نیاز در سال 2007 معرفی شد و امکان استفاده از GPU ها را برای محاسبات غیر گرافیکی به برنامهنویسان ارائه داد.
مفهوم اصلی CUDA بر پایه استفاده از GPU به عنوان یک شتابدهنده محاسباتی در کنار CPU (واحد پردازش مرکزی) است. به طور سنتی، CPU مسئولیت اجرای بخش عمدهای از کد برنامه را بر عهده دارد، اما بخشهایی از کد که قابلیت موازیسازی دارند و نیاز به پردازش محاسباتی سنگین دارند، میتوانند به GPU منتقل شوند تا با سرعت بسیار بیشتری اجرا شوند. این رویکرد به عنوان محاسبات ناهمگن (Heterogeneous Computing) شناخته میشود.
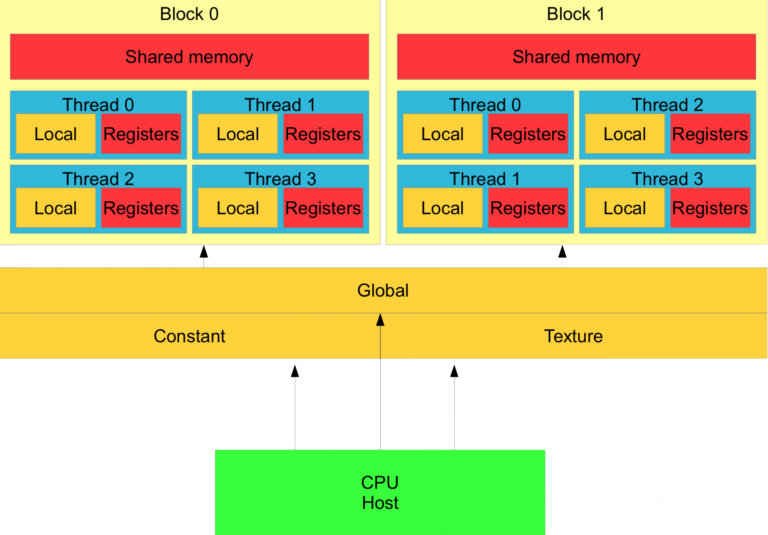
معماری CUDA
معماری CUDA شامل دو بخش اصلی است: میزبان (Host) و دستگاه (Device).
- میزبان (
Host): میزبان معمولاًCPUو حافظه سیستم است که مسئولیت اجرای بخش اصلی برنامه، مدیریت حافظه و ارسال وظایف محاسباتی به دستگاه را بر عهده دارد. - دستگاه (
Device): دستگاه معمولاًGPUو حافظهGPUاست که وظیفه اجرای محاسبات موازی سنگین را بر عهده دارد.GPUدر معماریCUDAاز تعداد زیادی هسته پردازشی کوچک و سبکوزن (هستههایCUDA) تشکیل شده است که به طور همزمان میتوانند هزاران رشته (thread) را اجرا کنند.
سازماندهی هستههای CUDA در GPU به صورت سلسله مراتبی انجام میشود:
- هسته (
Kernel): هسته، یک تابعCUDAاست که بر رویGPUاجرا میشود. هر هسته برای اجرای بخش خاصی از محاسبات طراحی شده است و به صورت موازی بر روی تعداد زیادی داده اجرا میشود. - رشته (
Thread): رشته، کوچکترین واحد اجرای موازی درCUDAاست. هر رشته، یک کپی از هسته را اجرا میکند و بر روی یک بخش از دادهها عمل میکند. - بلوک (
Block): بلوک، مجموعهای از رشتهها است که با هم همکاری میکنند و میتوانند از حافظه مشترک (Shared Memory) برای تبادل داده استفاده کنند. رشتههای درون یک بلوک بر روی یک پردازنده چند جریانی (Streaming Multiprocessor - SM) اجرا میشوند. - شبکه (
Grid): شبکه، مجموعهای از بلوکها است که با هم یک هسته را اجرا میکنند. بلوکهای درون یک شبکه به طور مستقل از یکدیگر اجرا میشوند و نمیتوانند به طور مستقیم از حافظه مشترک یکدیگر استفاده کنند.

مدل برنامهنویسی CUDA
مدل برنامهنویسی CUDA بر پایه توسعه زبان C++ ساخته شده است و مجموعهای از کلمات کلیدی و توابع را ارائه میدهد که به برنامهنویسان اجازه میدهد تا هستههای CUDA را تعریف کرده و اجرای آنها را بر روی GPU مدیریت کنند.
مراحل اصلی برنامهنویسی CUDA به شرح زیر است:
- انتقال داده از میزبان به دستگاه: ابتدا دادههای مورد نیاز برای محاسبات باید از حافظه سیستم (حافظه میزبان) به حافظه
GPU(حافظه دستگاه) منتقل شوند. این کار با استفاده از توابعAPI CUDAمانندcudaMemcpy()انجام میشود. - اجرای هسته بر روی دستگاه: هسته
CUDAبا استفاده از ساختار<<<grid, block>>>فراخوانی میشود. این ساختار مشخص میکند که هسته با چه تعداد بلوک و چه تعداد رشته در هر بلوک باید اجرا شود. - انتقال داده از دستگاه به میزبان: پس از اتمام محاسبات بر روی
GPU، نتایج باید از حافظهGPUبه حافظه سیستم منتقل شوند تا برنامه میزبان بتواند از آنها استفاده کند. این کار نیز با استفاده از تابعcudaMemcpy()انجام میشود.
مدیریت حافظه در CUDA
CUDA دارای یک سلسله مراتب حافظه است که شامل انواع مختلفی از حافظه با سرعت و ظرفیت متفاوت است. مدیریت صحیح حافظه در CUDA برای دستیابی به حداکثر کارایی بسیار مهم است. انواع اصلی حافظه در CUDA عبارتند از:
- حافظه سراسری (
Global Memory): حافظه اصلیGPUاست که برای ذخیره دادههای بزرگ و قابل دسترس برای همه رشتهها استفاده میشود. حافظه سراسری دارای ظرفیت بالا اما سرعت دسترسی نسبتاً پایین است. - حافظه مشترک (
Shared Memory): حافظه سریع و کم ظرفیت که درون هر پردازنده چند جریانی (SM) قرار دارد و به رشتههای درون یک بلوک اجازه میدهد تا به سرعت دادهها را به اشتراک بگذارند. حافظه مشترک برای بهینهسازی دسترسی به دادههای پرکاربرد بسیار مفید است. - ثباتها (
Registers): حافظه بسیار سریع و کم ظرفیت که برای ذخیره متغیرهای محلی هر رشته استفاده میشود. دسترسی به ثباتها بسیار سریع است اما ظرفیت آنها محدود است. - حافظه ثابت (
Constant Memory): حافظه فقط خواندنی که برای ذخیره دادههای ثابت و مشترک بین همه رشتهها استفاده میشود. حافظه ثابت از طریق کش (Cache) به دادهها دسترسی دارد و برای دادههایی که به طور مکرر خوانده میشوند مناسب است. - حافظه بافت (
Texture Memory): حافظه فقط خواندنی که برای دادههای بافت و دادههایی که نیاز به دسترسی غیر مستقیم دارند مناسب است. حافظه بافت از طریق کش و واحدهای بافتسازی سختافزاری به دادهها دسترسی دارد.
ابزارها و کتابخانههای CUDA
NVIDIA مجموعه گستردهای از ابزارها و کتابخانهها را برای توسعه برنامههای CUDA ارائه میدهد که فرآیند توسعه را تسهیل و کارایی برنامهها را افزایش میدهد. برخی از ابزارهای مهم CUDA عبارتند از:
nvcc(NVIDIA CUDA Compiler): کامپایلرCUDAاست که کدCUDAرا به کد اجرایی برایGPUتبدیل میکند.CUDA Profiler: ابزاری برای تجزیه و تحلیل عملکرد برنامههایCUDAو شناسایی گلوگاههای عملکردی.CUDA Debugger: ابزاری برای اشکالزدایی برنامههایCUDAو پیدا کردن خطاها.
همچنین، NVIDIA کتابخانههای تخصصی متعددی را برای کاربردهای مختلف ارائه میدهد که از محاسبات CUDA استفاده میکنند. برخی از کتابخانههای مهم CUDA عبارتند از:
cuBLAS (CUDA Basic Linear Algebra Subroutines): کتابخانه برای عملیات جبر خطی پایه مانند ضرب ماتریسها، حل معادلات خطی و غیره.cuFFT (CUDA Fast Fourier Transform): کتابخانه برای محاسبه تبدیل فوریه سریع (FFT) که در پردازش سیگنال و تصویر کاربرد فراوانی دارد.cuDNN (CUDA Deep Neural Network library): کتابخانه برای توسعه شبکههای عصبی عمیق که عملیات پایه شبکههای عصبی را به صورت بهینه شده بر رویGPUاجرا میکند.cuSPARSE (CUDA Sparse Matrix library): کتابخانه برای عملیات جبر خطی بر روی ماتریسهای خلوت (Sparse Matrix) که در بسیاری از مسائل علمی و مهندسی کاربرد دارند.
کاربردهای CUDA
CUDA به طور گسترده در طیف وسیعی از کاربردها مورد استفاده قرار میگیرد که نیاز به محاسبات موازی سنگین دارند. برخی از کاربردهای مهم CUDA عبارتند از:
- یادگیری عمیق (
Deep Learning):CUDAنقش کلیدی در پیشرفت یادگیری عمیق داشته است.GPUها به دلیل قدرت پردازش موازی بالا، برای آموزش شبکههای عصبی عمیق بسیار مناسب هستند و کتابخانههایی مانندcuDNNفرآیند توسعه و اجرای شبکههای عصبی را به طور چشمگیری تسریع میکنند. - محاسبات علمی (
Scientific Computing):CUDAدر زمینههای مختلف محاسبات علمی مانند شبیهسازی دینامیک سیالات، مدلسازی مولکولی، هواشناسی، فیزیک ذرات و غیره به طور گسترده استفاده میشود. - پردازش تصویر و ویدئو (
Image and Video Processing):CUDAبرای پردازش تصاویر و ویدئو با سرعت بالا، مانند فیلتر کردن تصاویر، تشخیص اشیا، رمزگشایی ویدئو و غیره استفاده میشود. - امور مالی (
Finance):CUDAدر امور مالی برای محاسبات پیچیده مالی مانند مدلسازی ریسک، تحلیل بازارهای مالی و معاملات الگوریتمی استفاده میشود. - بیوانفورماتیک (
Bioinformatics):CUDAدر بیوانفورماتیک برای تجزیه و تحلیل دادههای ژنومیک، پروتئومیک و شبیهسازی ساختار مولکولهای زیستی استفاده میشود.
مزایای CUDA
استفاده از CUDA مزایای متعددی را برای برنامهنویسان و توسعهدهندگان نرمافزار ارائه میدهد:
- افزایش کارایی (
Performance Gain):CUDAبه برنامهنویسان اجازه میدهد تا از قدرت پردازش موازی بالایGPUبرای اجرای برنامههای خود استفاده کنند و به طور قابل توجهی کارایی برنامههایی که نیاز به محاسبات سنگین دارند را افزایش دهند. در برخی موارد، برنامههایCUDAمیتوانند دهها یا حتی صدها برابر سریعتر از معادلCPUخود اجرا شوند. - موازیسازی آسان (
Ease of Parallelization): مدل برنامهنویسیCUDAمفهوم موازیسازی را برای برنامهنویسان سادهتر میکند. کلمات کلیدی و توابعAPI CUDAبه برنامهنویسان اجازه میدهند تا به راحتی بخشهای قابل موازیسازی کد خود را شناسایی کرده و برای اجرا بر رویGPUآماده کنند. - دسترسی گسترده (
Wide Availability):GPUهایNVIDIAبه طور گسترده در دسترس هستند و در انواع سیستمهای کامپیوتری از جمله رایانههای شخصی، ایستگاههای کاری و ابررایانهها استفاده میشوند. این امر دسترسی بهCUDAرا برای طیف وسیعی از برنامهنویسان و محققان فراهم میکند. - اکوسیستم غنی (
Rich Ecosystem):NVIDIAاکوسیستم غنی از ابزارها، کتابخانهها و منابع آموزشی را برای توسعهCUDAفراهم کرده است که فرآیند توسعه را تسهیل و سرعت میبخشد.
نتیجهگیری
CUDA به عنوان یک معماری محاسباتی موازی و مدل برنامهنویسی قدرتمند، نقش بسیار مهمی در پیشرفت محاسبات موازی و کاربردهای آن ایفا کرده است. CUDA به برنامهنویسان امکان میدهد تا از قدرت پردازشی عظیم GPU های NVIDIA برای حل مسائل پیچیده و پردازش حجم عظیمی از دادهها استفاده کنند. با توجه به افزایش روزافزون پیچیدگی مسائل محاسباتی و نیاز به سرعت پردازش بالاتر، CUDA به عنوان یک فناوری کلیدی در آینده محاسبات، جایگاه خود را حفظ خواهد کرد و به توسعه کاربردهای جدید محاسبات موازی کمک خواهد کرد.